.png)
Most AI teams absorption connected the incorrect things. Here’s a communal country from my consulting work:
AI TEAM
Here’s our cause architecture—we’ve got RAG here, a router there, and we’re utilizing this caller model for…
ME
[Holding up my manus to intermission the enthusiastic tech lead]
Can you amusement maine however you’re measuring if immoderate of this really works?
… Room goes quiet

Learn faster. Dig deeper. See farther.
This country has played retired dozens of times implicit the past 2 years. Teams put weeks gathering analyzable AI systems but can’t archer maine if their changes are helping oregon hurting.
This isn’t surprising. With caller tools and frameworks emerging weekly, it’s earthy to absorption connected tangible things we tin control—which vector database to use, which LLM supplier to choose, which cause model to adopt. But aft helping 30+ companies physique AI products, I’ve discovered that the teams who win hardly speech astir tools astatine all. Instead, they obsess implicit measurement and iteration.
In this post, I’ll amusement you precisely however these palmy teams operate. While each concern is unique, you’ll spot patterns that use careless of your domain oregon squad size. Let’s commencement by examining the astir communal mistake I spot teams make—one that derails AI projects earlier they adjacent begin.
The Most Common Mistake: Skipping Error Analysis
The “tools first” mindset is the astir communal mistake successful AI development. Teams get caught up successful architecture diagrams, frameworks, and dashboards portion neglecting the process of really knowing what’s moving and what isn’t.
One lawsuit proudly showed maine this valuation dashboard:
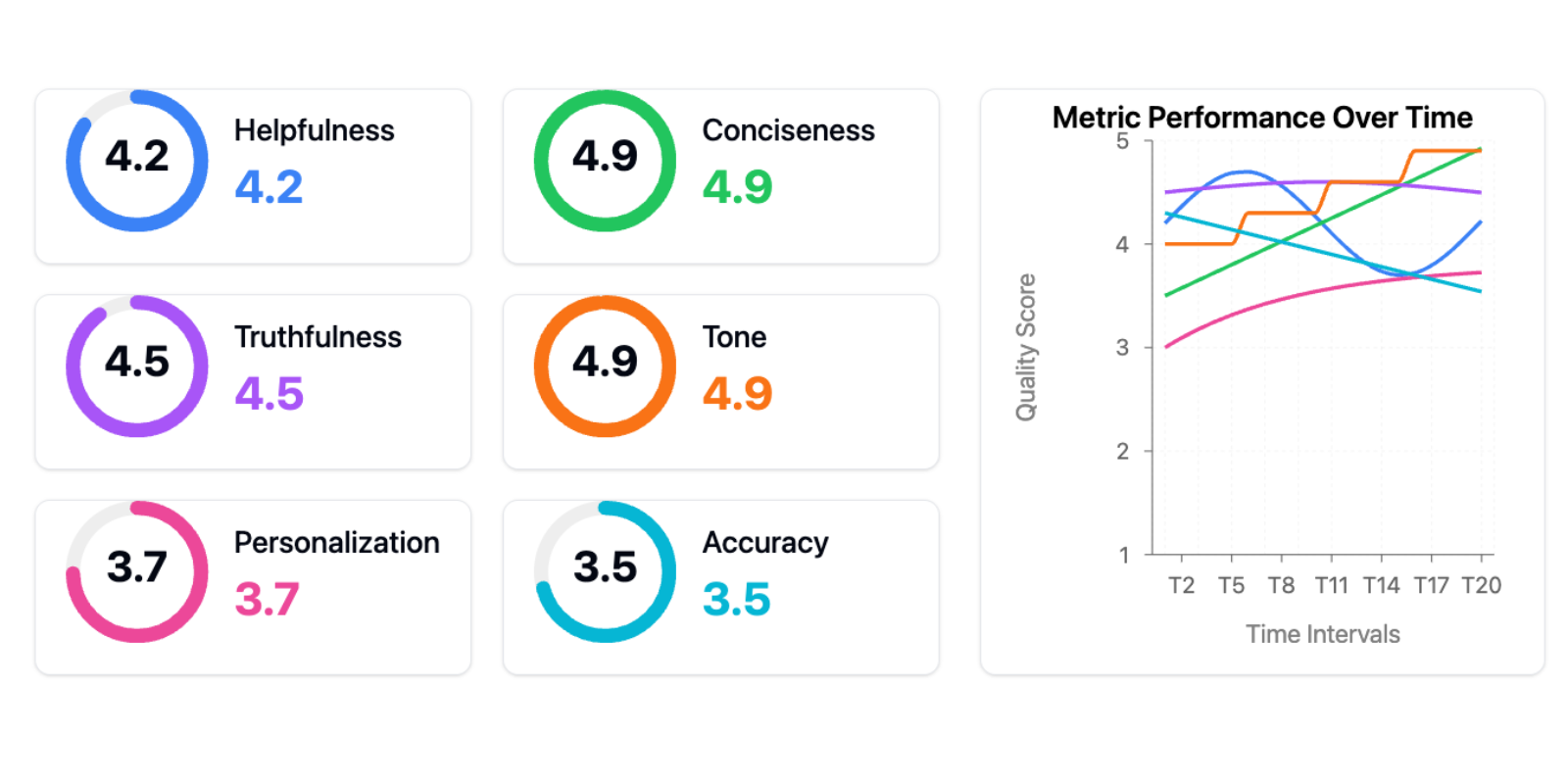 The benignant of dashboard that foreshadows failure
The benignant of dashboard that foreshadows failureThis is the “tools trap”—the content that adopting the close tools oregon frameworks (in this case, generic metrics) volition lick your AI problems. Generic metrics are worse than useless—they actively impede advancement successful 2 ways:
First, they make a mendacious consciousness of measurement and progress. Teams deliberation they’re data-driven due to the fact that they person dashboards, but they’re tracking vanity metrics that don’t correlate with existent idiosyncratic problems. I’ve seen teams observe improving their “helpfulness score” by 10% portion their existent users were inactive struggling with basal tasks. It’s similar optimizing your website’s load clip portion your checkout process is broken—you’re getting amended astatine the incorrect thing.
Second, excessively galore metrics fragment your attention. Instead of focusing connected the fewer metrics that substance for your circumstantial usage case, you’re trying to optimize aggregate dimensions simultaneously. When everything is important, thing is.
The alternative? Error analysis: the azygous astir invaluable enactment successful AI improvement and consistently the highest-ROI activity. Let maine amusement you what effectual mistake investigation looks similar successful practice.
The Error Analysis Process
When Jacob, the laminitis of Nurture Boss, needed to amended the company’s apartment-industry AI assistant, his squad built a elemental spectator to analyse conversations betwixt their AI and users. Next to each speech was a abstraction for open-ended notes astir nonaccomplishment modes.
After annotating dozens of conversations, wide patterns emerged. Their AI was struggling with day handling—failing 66% of the clip erstwhile users said things similar “Let’s docket a circuit 2 weeks from now.”
Instead of reaching for caller tools, they:
- Looked astatine existent speech logs
- Categorized the types of date-handling failures
- Built circumstantial tests to drawback these issues
- Measured betterment connected these metrics
The result? Their day handling occurrence complaint improved from 33% to 95%.
Here’s Jacob explaining this process himself:
Bottom-Up Versus Top-Down Analysis
When identifying mistake types, you tin instrumentality either a “top-down” oregon “bottom-up” approach.
The top-down attack starts with communal metrics similar “hallucination” oregon “toxicity” positive metrics unsocial to your task. While convenient, it often misses domain-specific issues.
The much effectual bottom-up attack forces you to look astatine existent information and fto metrics people emerge. At Nurture Boss, we started with a spreadsheet wherever each enactment represented a conversation. We wrote open-ended notes connected immoderate undesired behavior. Then we utilized an LLM to physique a taxonomy of communal nonaccomplishment modes. Finally, we mapped each enactment to circumstantial nonaccomplishment mode labels and counted the frequence of each issue.
The results were striking—just 3 issues accounted for implicit 60% of each problems:
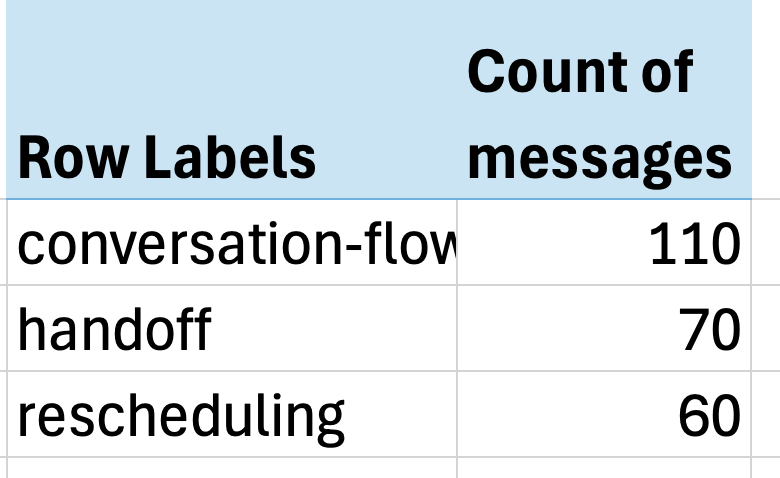 Excel PivotTables are a elemental tool, but they work!
Excel PivotTables are a elemental tool, but they work!- Conversation travel issues (missing context, awkward responses)
- Handoff failures (not recognizing erstwhile to transportation to humans)
- Rescheduling problems (struggling with day handling)
The interaction was immediate. Jacob’s squad had uncovered truthful galore actionable insights that they needed respective weeks conscionable to instrumentality fixes for the problems we’d already found.
If you’d similar to spot mistake investigation successful action, we recorded a live walkthrough here.
This brings america to a important question: How bash you marque it casual for teams to look astatine their data? The reply leads america to what I see the astir important concern immoderate AI squad tin make…
The Most Important AI Investment: A Simple Data Viewer
The azygous astir impactful concern I’ve seen AI teams marque isn’t a fancy valuation dashboard—it’s gathering a customized interface that lets anyone analyse what their AI is really doing. I stress customized due to the fact that each domain has unsocial needs that off-the-shelf tools seldom address. When reviewing flat leasing conversations, you request to spot the afloat chat past and scheduling context. For real-estate queries, you request the spot details and root documents close there. Even tiny UX decisions—like wherever to spot metadata oregon which filters to expose—can marque the quality betwixt a instrumentality radical really usage and 1 they avoid.
I’ve watched teams conflict with generic labeling interfaces, hunting done aggregate systems conscionable to recognize a azygous interaction. The friction adds up: clicking done to antithetic systems to spot context, copying mistake descriptions into abstracted tracking sheets, switching betwixt tools to verify information. This friction doesn’t conscionable dilatory teams down—it actively discourages the benignant of systematic investigation that catches subtle issues.
Teams with thoughtfully designed information viewers iterate 10x faster than those without them. And here’s the thing: These tools tin beryllium built successful hours utilizing AI-assisted improvement (like Cursor oregon Loveable). The concern is minimal compared to the returns.
Let maine amusement you what I mean. Here’s the information spectator built for Nurture Boss (which I discussed earlier):
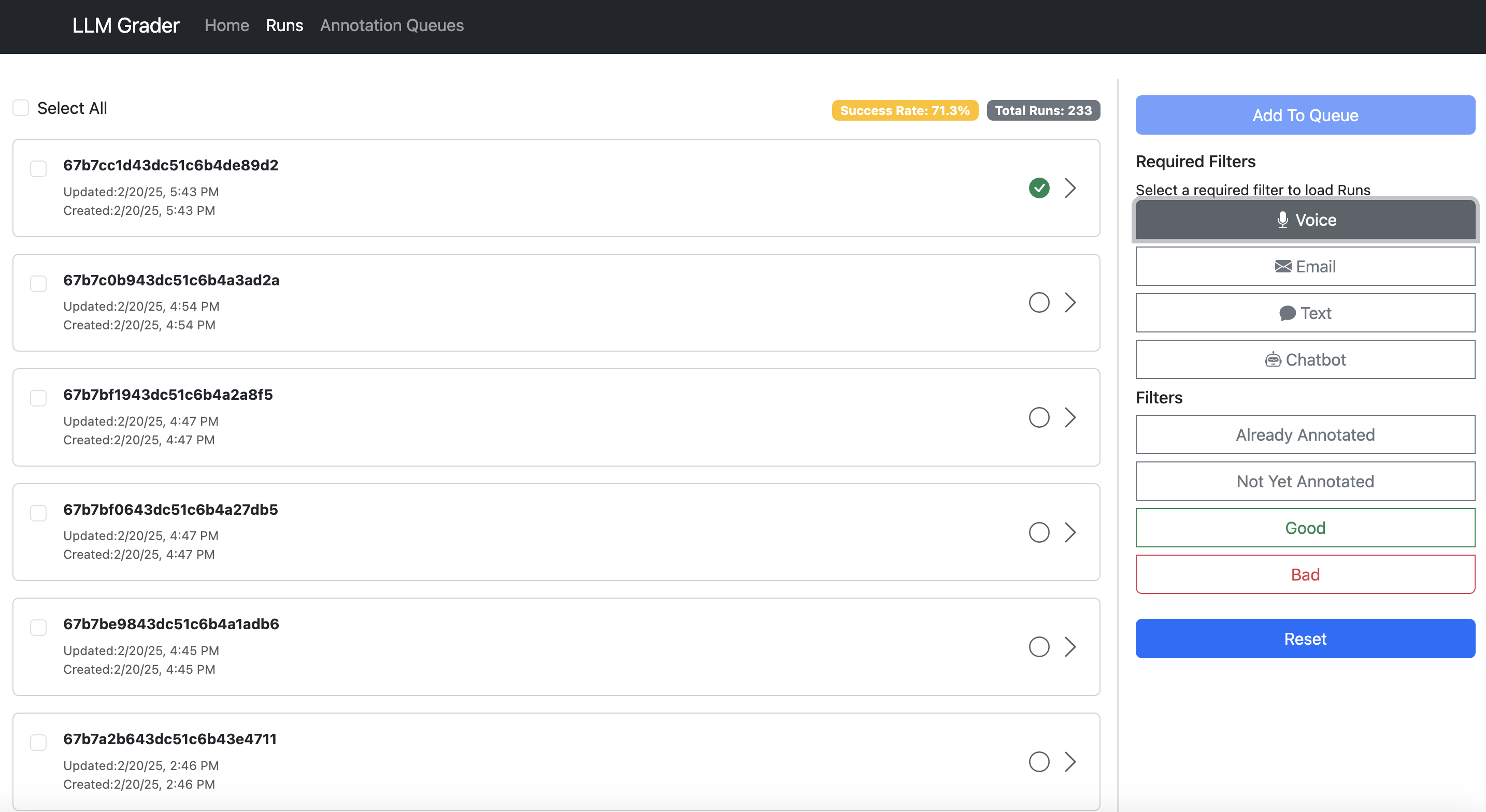 Search and filter sessions.
Search and filter sessions.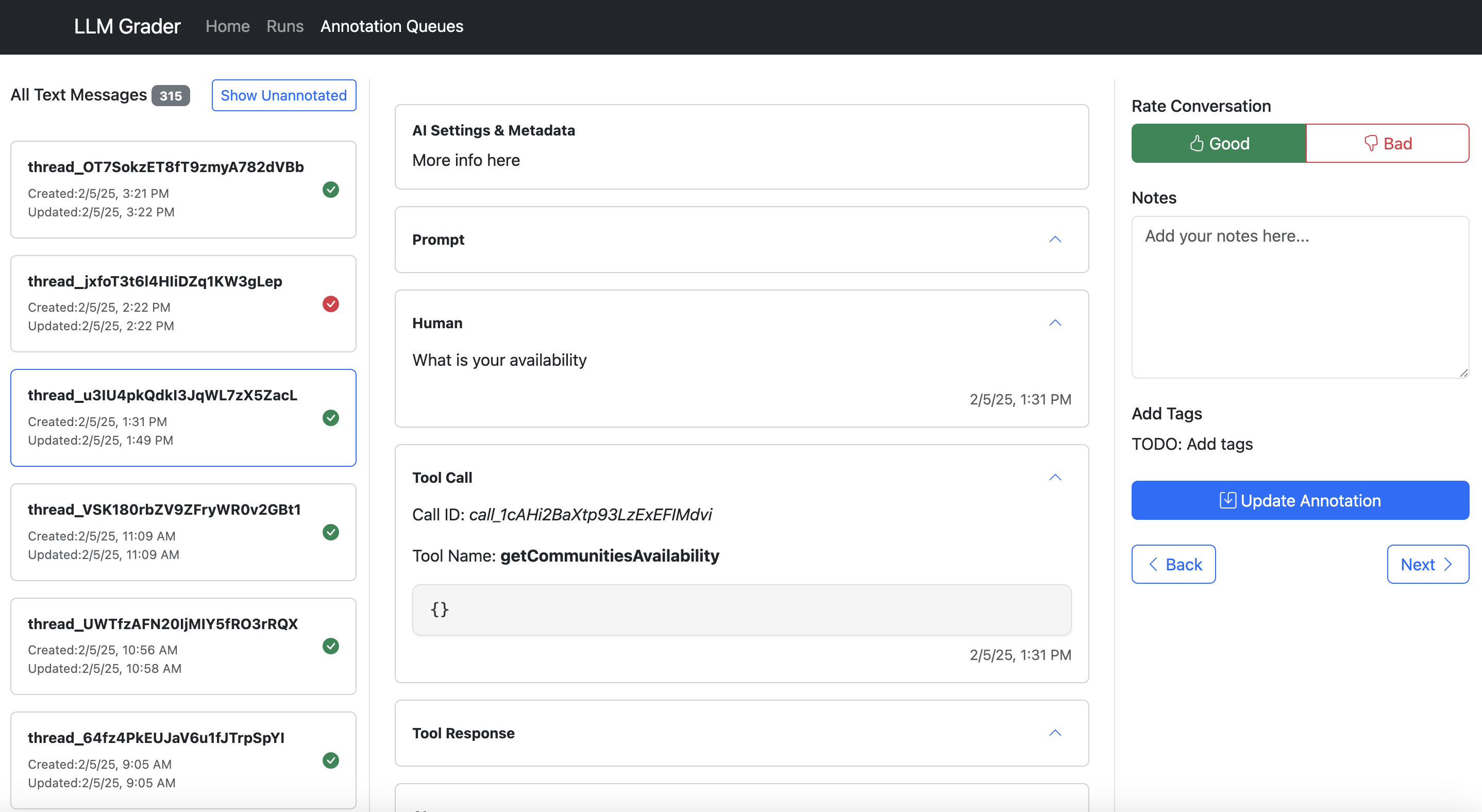 Annotate and adhd notes.
Annotate and adhd notes.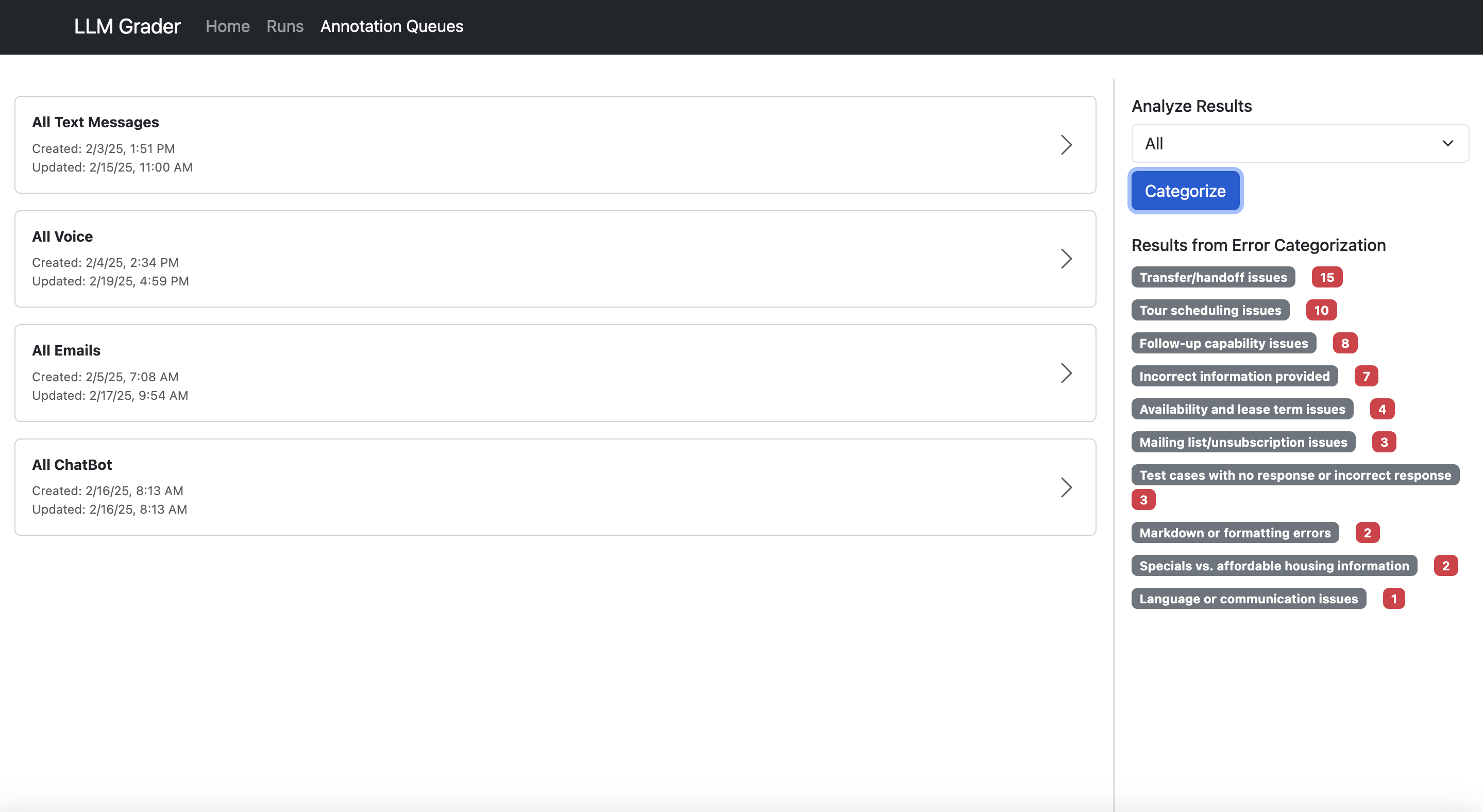 Aggregate and number errors.
Aggregate and number errors.Here’s what makes a bully information annotation tool:
- Show each discourse successful 1 place. Don’t marque users hunt done antithetic systems to recognize what happened.
- Make feedback trivial to capture. One-click correct/incorrect buttons bushed lengthy forms.
- Capture open-ended feedback. This lets you seizure nuanced issues that don’t acceptable into a predefined taxonomy.
- Enable speedy filtering and sorting. Teams request to easy dive into circumstantial mistake types. In the illustration above, Nurture Boss tin rapidly filter by the transmission (voice, text, chat) oregon the circumstantial spot they privation to look astatine quickly.
- Have hotkeys that let users to navigate betwixt information examples and annotate without clicking.
It doesn’t substance what web frameworks you use—use immoderate you’re acquainted with. Because I’m a Python developer, my existent favourite web model is FastHTML coupled with MonsterUI due to the fact that it allows maine to specify the backend and frontend codification successful 1 tiny Python file.
The cardinal is starting somewhere, adjacent if it’s simple. I’ve recovered customized web apps supply the champion experience, but if you’re conscionable beginning, a spreadsheet is amended than nothing. As your needs grow, you tin germinate your tools accordingly.
This brings america to different counterintuitive lesson: The radical champion positioned to amended your AI strategy are often the ones who cognize the slightest astir AI.
Empower Domain Experts to Write Prompts
I precocious worked with an acquisition startup gathering an interactive learning level with LLMs. Their merchandise manager, a learning plan expert, would make elaborate PowerPoint decks explaining pedagogical principles and illustration dialogues. She’d contiguous these to the engineering team, who would past construe her expertise into prompts.
But here’s the thing: Prompts are conscionable English. Having a learning adept pass teaching principles done PowerPoint lone for engineers to construe that backmost into English prompts created unnecessary friction. The astir palmy teams flip this exemplary by giving domain experts tools to constitute and iterate connected prompts directly.
Build Bridges, Not Gatekeepers
Prompt playgrounds are a large starting constituent for this. Tools similar Arize, LangSmith, and Braintrust fto teams rapidly trial antithetic prompts, provender successful illustration datasets, and comparison results. Here are immoderate screenshots of these tools:
 Arize Phoenix
Arize Phoenix LangSmith
LangSmith Braintrust
BraintrustBut there’s a important adjacent measurement that galore teams miss: integrating punctual improvement into their exertion context. Most AI applications aren’t conscionable prompts; they commonly impact RAG systems pulling from your cognition base, cause orchestration coordinating aggregate steps, and application-specific concern logic. The astir effectual teams I’ve worked with spell beyond stand-alone playgrounds. They physique what I telephone integrated punctual environments—essentially admin versions of their existent idiosyncratic interface that exposure punctual editing.
Here’s an illustration of what an integrated punctual situation mightiness look similar for a real-estate AI assistant:
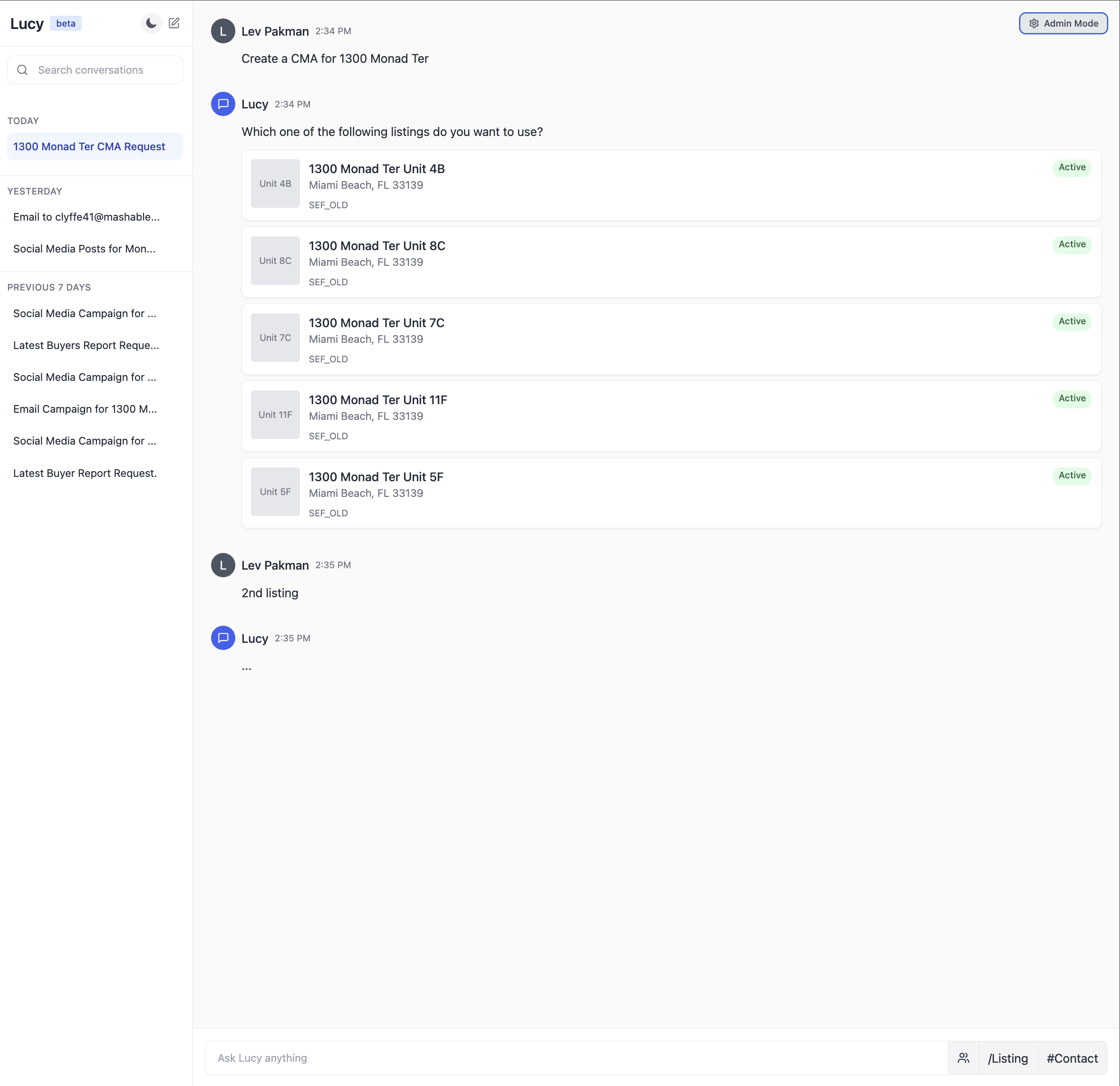 The UI that users (real-estate agents) see
The UI that users (real-estate agents) see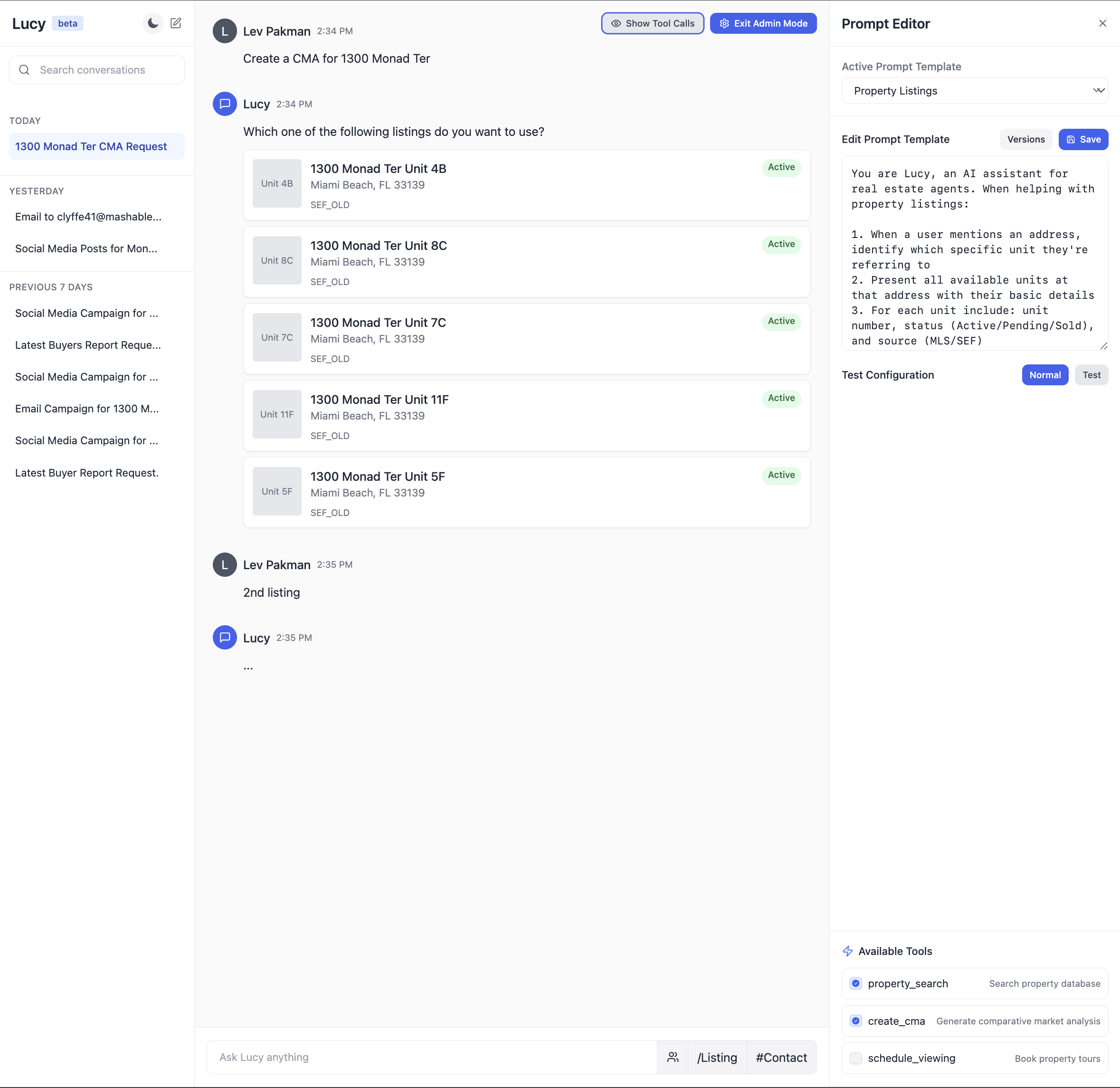 The aforesaid UI, but with an “admin mode” utilized by the engineering and merchandise squad to iterate connected the punctual and debug issues
The aforesaid UI, but with an “admin mode” utilized by the engineering and merchandise squad to iterate connected the punctual and debug issuesTips for Communicating With Domain Experts
There’s different obstruction that often prevents domain experts from contributing effectively: unnecessary jargon. I was moving with an acquisition startup wherever engineers, merchandise managers, and learning specialists were talking past each different successful meetings. The engineers kept saying, “We’re going to physique an cause that does XYZ,” erstwhile truly the occupation to beryllium done was penning a prompt. This created an artificial barrier—the learning specialists, who were the existent domain experts, felt similar they couldn’t lend due to the fact that they didn’t recognize “agents.”
This happens everywhere. I’ve seen it with lawyers astatine ineligible tech companies, psychologists astatine intelligence wellness startups, and doctors astatine healthcare firms. The magic of LLMs is that they marque AI accessible done earthy language, but we often destruct that vantage by wrapping everything successful method terminology.
Here’s a elemental illustration of however to construe communal AI jargon:
| Instead of saying… | Say… |
| “We’re implementing a RAG approach.” | “We’re making definite the exemplary has the close discourse to reply questions.” |
| “We request to forestall punctual injection.” | “We request to marque definite users can’t instrumentality the AI into ignoring our rules.” |
| “Our exemplary suffers from hallucination issues.” | “Sometimes the AI makes things up, truthful we request to cheque its answers.” |
This doesn’t mean dumbing things down—it means being precise astir what you’re really doing. When you say, “We’re gathering an agent,” what circumstantial capableness are you adding? Is it relation calling? Tool use? Or conscionable a amended prompt? Being circumstantial helps everyone recognize what’s really happening.
There’s nuance here. Technical terminology exists for a reason: it provides precision erstwhile talking with different method stakeholders. The cardinal is adapting your connection to your audience.
The situation galore teams rise astatine this constituent is “This each sounds great, but what if we don’t person immoderate information yet? How tin we look astatine examples oregon iterate connected prompts erstwhile we’re conscionable starting out?” That’s what we’ll speech astir next.
Bootstrapping Your AI With Synthetic Data Is Effective (Even With Zero Users)
One of the astir communal roadblocks I perceive from teams is “We can’t bash due valuation due to the fact that we don’t person capable existent idiosyncratic information yet.” This creates a chicken-and-egg problem—you request information to amended your AI, but you request a decent AI to get users who make that data.
Fortunately, there’s a solution that works amazingly well: synthetic data. LLMs tin make realistic trial cases that screen the scope of scenarios your AI volition encounter.
As I wrote successful my LLM-as-a-Judge blog post, synthetic information tin beryllium remarkably effectual for evaluation. Bryan Bischof, the erstwhile caput of AI astatine Hex, enactment it perfectly:
LLMs are amazingly bully astatine generating fantabulous – and divers – examples of idiosyncratic prompts. This tin beryllium applicable for powering exertion features, and sneakily, for gathering Evals. If this sounds a spot similar the Large Language Snake is eating its tail, I was conscionable arsenic amazed arsenic you! All I tin accidental is: it works, vessel it.
A Framework for Generating Realistic Test Data
The cardinal to effectual synthetic information is choosing the close dimensions to test. While these dimensions volition alteration based connected your circumstantial needs, I find it adjuvant to deliberation astir 3 wide categories:
- Features: What capabilities does your AI request to support?
- Scenarios: What situations volition it encounter?
- User personas: Who volition beryllium utilizing it and how?
These aren’t the lone dimensions you mightiness attraction about—you mightiness besides privation to trial antithetic tones of voice, levels of method sophistication, oregon adjacent antithetic locales and languages. The important happening is identifying dimensions that substance for your circumstantial usage case.
For a real-estate CRM AI adjunct I worked connected with Rechat, we defined these dimensions similar this:

But having these dimensions defined is lone fractional the battle. The existent situation is ensuring your synthetic information really triggers the scenarios you privation to test. This requires 2 things:
- A trial database with capable assortment to enactment your scenarios
- A mode to verify that generated queries really trigger intended scenarios
For Rechat, we maintained a trial database of listings that we knew would trigger antithetic borderline cases. Some teams similar to usage an anonymized transcript of accumulation data, but either way, you request to guarantee your trial information has capable assortment to workout the scenarios you attraction about.
Here’s an illustration of however we mightiness usage these dimensions with existent information to make trial cases for the spot hunt diagnostic (this is conscionable pseudo code, and precise illustrative):
def generate_search_query(scenario, persona, listing_db): """Generate a realistic idiosyncratic query astir listings""" # Pull existent listing information to crushed the generation sample_listings = listing_db.get_sample_listings( price_range=persona.price_range, location=persona.preferred_areas ) # Verify we person listings that volition trigger our scenario if script == "multiple_matches" and len(sample_listings) 0: rise ValueError("Found matches erstwhile investigating no-match scenario") punctual = f""" You are an adept existent property cause who is searching for listings. You are fixed a lawsuit benignant and a scenario. Your occupation is to make a earthy connection query you would usage to hunt these listings. Context: - Customer type: {persona.description} - Scenario: {scenario} Use these existent listings arsenic reference: {format_listings(sample_listings)} The query should bespeak the lawsuit benignant and the scenario. Example query: Find homes successful the 75019 zip code, 3 bedrooms, 2 bathrooms, terms scope $750k - $1M for an investor. """ instrumentality generate_with_llm(prompt)This produced realistic queries like:
| property search | multiple matches | first_time_buyer | “Looking for 3-bedroom homes nether $500k successful the Riverside area. Would emotion thing adjacent to parks since we person young kids.” |
| market analysis | no matches | investor | “Need comps for 123 Oak St. Specifically funny successful rental output examination with akin properties successful a 2-mile radius.” |
The cardinal to utile synthetic information is grounding it successful existent strategy constraints. For the real-estate AI assistant, this means:
- Using existent listing IDs and addresses from their database
- Incorporating existent cause schedules and availability windows
- Respecting concern rules similar showing restrictions and announcement periods
- Including market-specific details similar HOA requirements oregon section regulations
We past provender these trial cases done Lucy (now portion of Capacity) and log the interactions. This gives america a affluent dataset to analyze, showing precisely however the AI handles antithetic situations with existent strategy constraints. This attack helped america hole issues earlier they affected existent users.
Sometimes you don’t person entree to a accumulation database, particularly for caller products. In these cases, usage LLMs to make some trial queries and the underlying trial data. For a real-estate AI assistant, this mightiness mean creating synthetic spot listings with realistic attributes—prices that lucifer marketplace ranges, valid addresses with existent thoroughfare names, and amenities due for each spot type. The cardinal is grounding synthetic information successful real-world constraints to marque it utile for testing. The specifics of generating robust synthetic databases are beyond the scope of this post.
Guidelines for Using Synthetic Data
When generating synthetic data, travel these cardinal principles to guarantee it’s effective:
- Diversify your dataset: Create examples that screen a wide scope of features, scenarios, and personas. As I wrote successful my LLM-as-a-Judge post, this diverseness helps you place borderline cases and nonaccomplishment modes you mightiness not expect otherwise.
- Generate idiosyncratic inputs, not outputs: Use LLMs to make realistic idiosyncratic queries oregon inputs, not the expected AI responses. This prevents your synthetic information from inheriting the biases oregon limitations of the generating model.
- Incorporate existent strategy constraints: Ground your synthetic information successful existent strategy limitations and data. For example, erstwhile investigating a scheduling feature, usage existent availability windows and booking rules.
- Verify script coverage: Ensure your generated information really triggers the scenarios you privation to test. A query intended to trial “no matches found” should really instrumentality zero results erstwhile tally against your system.
- Start simple, past adhd complexity: Begin with straightforward trial cases earlier adding nuance. This helps isolate issues and found a baseline earlier tackling borderline cases.
This attack isn’t conscionable theoretical—it’s been proven successful accumulation crossed dozens of companies. What often starts arsenic a stopgap measurement becomes a imperishable portion of the valuation infrastructure, adjacent aft existent idiosyncratic information becomes available.
Let’s look astatine however to support spot successful your valuation strategy arsenic you scale.
Maintaining Trust In Evals Is Critical
This is simply a signifier I’ve seen repeatedly: Teams physique valuation systems, past gradually suffer religion successful them. Sometimes it’s due to the fact that the metrics don’t align with what they observe successful production. Other times, it’s due to the fact that the evaluations go excessively analyzable to interpret. Either way, the effect is the same: The squad reverts to making decisions based connected gut feeling and anecdotal feedback, undermining the full intent of having evaluations.
Maintaining spot successful your valuation strategy is conscionable arsenic important arsenic gathering it successful the archetypal place. Here’s however the astir palmy teams attack this challenge.
Understanding Criteria Drift
One of the astir insidious problems successful AI valuation is “criteria drift”—a improvement wherever valuation criteria germinate arsenic you observe much exemplary outputs. In their insubstantial “Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences,” Shankar et al. picture this phenomenon:
To people outputs, radical request to externalize and specify their valuation criteria; however, the process of grading outputs helps them to specify that precise criteria.
This creates a paradox: You can’t afloat specify your valuation criteria until you’ve seen a wide scope of outputs, but you request criteria to measure those outputs successful the archetypal place. In different words, it is intolerable to wholly find valuation criteria anterior to quality judging of LLM outputs.
I’ve observed this firsthand erstwhile moving with Phillip Carter astatine Honeycomb connected the company’s Query Assistant feature. As we evaluated the AI’s quality to make database queries, Phillip noticed thing interesting:
Seeing however the LLM breaks down its reasoning made maine recognize I wasn’t being accordant astir however I judged definite borderline cases.
The process of reviewing AI outputs helped him articulate his ain valuation standards much clearly. This isn’t a motion of mediocre planning—it’s an inherent diagnostic of moving with AI systems that nutrient divers and sometimes unexpected outputs.
The teams that support spot successful their valuation systems clasp this world alternatively than warring it. They dainty valuation criteria arsenic surviving documents that germinate alongside their knowing of the occupation space. They besides admit that antithetic stakeholders mightiness person antithetic (sometimes contradictory) criteria, and they enactment to reconcile these perspectives alternatively than imposing a azygous standard.
Creating Trustworthy Evaluation Systems
So however bash you physique valuation systems that stay trustworthy contempt criteria drift? Here are the approaches I’ve recovered astir effective:
1. Favor Binary Decisions Over Arbitrary Scales
As I wrote successful my LLM-as-a-Judge post, binary decisions supply clarity that much analyzable scales often obscure. When faced with a 1–5 scale, evaluators often conflict with the quality betwixt a 3 and a 4, introducing inconsistency and subjectivity. What precisely distinguishes “somewhat helpful” from “helpful”? These bound cases devour disproportionate intelligence vigor and make sound successful your valuation data. And adjacent erstwhile businesses usage a 1–5 scale, they inevitably inquire wherever to gully the enactment for “good enough” oregon to trigger intervention, forcing a binary determination anyway.
In contrast, a binary pass/fail forces evaluators to marque a wide judgment: Did this output execute its intent oregon not? This clarity extends to measuring progress—a 10% summation successful passing outputs is instantly meaningful, portion a 0.5-point betterment connected a 5-point standard requires interpretation.
I’ve recovered that teams who defy binary valuation often bash truthful due to the fact that they privation to seizure nuance. But nuance isn’t lost—it’s conscionable moved to the qualitative critique that accompanies the judgment. The critique provides affluent discourse astir wherefore thing passed oregon failed and what circumstantial aspects could beryllium improved, portion the binary determination creates actionable clarity astir whether betterment is needed astatine all.
2. Enhance Binary Judgments With Detailed Critiques
While binary decisions supply clarity, they enactment champion erstwhile paired with elaborate critiques that seizure the nuance of wherefore thing passed oregon failed. This operation gives you the champion of some worlds: clear, actionable metrics and affluent contextual understanding.
For example, erstwhile evaluating a effect that correctly answers a user’s question but contains unnecessary information, a bully critique mightiness read:
The AI successfully provided the marketplace investigation requested (PASS), but included excessive item astir vicinity demographics that wasn’t applicable to the concern question. This makes the effect longer than indispensable and perchance distracting.
These critiques service aggregate functions beyond conscionable explanation. They unit domain experts to externalize implicit knowledge—I’ve seen ineligible experts determination from vague feelings that thing “doesn’t dependable right” to articulating circumstantial issues with citation formats oregon reasoning patterns that tin beryllium systematically addressed.
When included arsenic few-shot examples successful justice prompts, these critiques amended the LLM’s quality to crushed astir analyzable borderline cases. I’ve recovered this attack often yields 15%–20% higher statement rates betwixt quality and LLM evaluations compared to prompts without illustration critiques. The critiques besides supply fantabulous earthy worldly for generating high-quality synthetic data, creating a flywheel for improvement.
3. Measure Alignment Between Automated Evals and Human Judgment
If you’re utilizing LLMs to measure outputs (which is often indispensable astatine scale), it’s important to regularly cheque however good these automated evaluations align with quality judgment.
This is peculiarly important fixed our earthy inclination to over-trust AI systems. As Shankar et al. enactment successful “Who Validates the Validators?,” the deficiency of tools to validate evaluator prime is concerning.
Research shows radical thin to over-rely and over-trust AI systems. For instance, successful 1 precocious illustration incident, researchers from MIT posted a pre-print connected arXiv claiming that GPT-4 could ace the MIT EECS exam. Within hours, [the] enactment [was] debunked. . .citing problems arising from over-reliance connected GPT-4 to people itself.
This overtrust occupation extends beyond self-evaluation. Research has shown that LLMs tin beryllium biased by elemental factors similar the ordering of options successful a acceptable oregon adjacent seemingly innocuous formatting changes successful prompts. Without rigorous quality validation, these biases tin silently undermine your valuation system.
When moving with Honeycomb, we tracked statement rates betwixt our LLM-as-a-judge and Phillip’s evaluations:
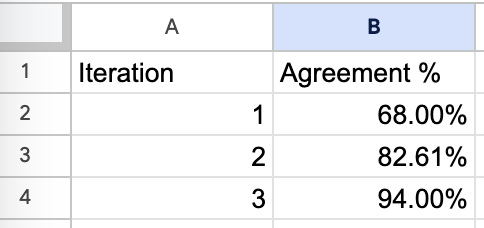 Agreement rates betwixt LLM evaluator and quality expert. More details here.
Agreement rates betwixt LLM evaluator and quality expert. More details here.It took 3 iterations to execute >90% agreement, but this concern paid disconnected successful a strategy the squad could trust. Without this validation step, automated evaluations often drift from quality expectations implicit time, particularly arsenic the organisation of inputs changes. You tin read much astir this here.
Tools similar Eugene Yan’s AlignEval show this alignment process beautifully. AlignEval provides a elemental interface wherever you upload data, statement examples with a binary “good” oregon “bad,” and past measure LLM-based judges against those quality judgments. What makes it effectual is however it streamlines the workflow—you tin rapidly spot wherever automated evaluations diverge from your preferences, refine your criteria based connected these insights, and measurement betterment implicit time. This attack reinforces that alignment isn’t a one-time setup but an ongoing speech betwixt quality judgement and automated evaluation.
Scaling Without Losing Trust
As your AI strategy grows, you’ll inevitably look unit to trim the quality effort progressive successful evaluation. This is wherever galore teams spell wrong—they automate excessively much, excessively quickly, and suffer the quality transportation that keeps their evaluations grounded.
The astir palmy teams instrumentality a much measured approach:
- Start with precocious quality involvement: In the aboriginal stages, person domain experts measure a important percent of outputs.
- Study alignment patterns: Rather than automating evaluation, absorption connected knowing wherever automated evaluations align with quality judgement and wherever they diverge. This helps you place which types of cases request much cautious quality attention.
- Use strategical sampling: Rather than evaluating each output, usage statistical techniques to illustration outputs that supply the astir information, peculiarly focusing connected areas wherever alignment is weakest.
- Maintain regular calibration: Even arsenic you scale, proceed to comparison automated evaluations against quality judgement regularly, utilizing these comparisons to refine your knowing of erstwhile to spot automated evaluations.
Scaling valuation isn’t conscionable astir reducing quality effort—it’s astir directing that effort wherever it adds the astir value. By focusing quality attraction connected the astir challenging oregon informative cases, you tin support prime adjacent arsenic your strategy grows.
Now that we’ve covered however to support spot successful your evaluations, let’s speech astir a cardinal displacement successful however you should attack AI improvement roadmaps.
Your AI Roadmap Should Count Experiments, Not Features
If you’ve worked successful bundle development, you’re acquainted with accepted roadmaps: a database of features with people transportation dates. Teams perpetrate to shipping circumstantial functionality by circumstantial deadlines, and occurrence is measured by however intimately they deed those targets.
This attack fails spectacularly with AI.
I’ve watched teams perpetrate to roadmap objectives similar “Launch sentiment investigation by Q2” oregon “Deploy agent-based lawsuit enactment by extremity of year,” lone to observe that the exertion simply isn’t acceptable to conscionable their prime bar. They either vessel thing subpar to deed the deadline oregon miss the deadline entirely. Either way, spot erodes.
The cardinal occupation is that accepted roadmaps presume we cognize what’s possible. With accepted software, that’s often true—given capable clip and resources, you tin physique astir features reliably. With AI, particularly astatine the cutting edge, you’re perpetually investigating the boundaries of what’s feasible.
Experiments Versus Features
Bryan Bischof, erstwhile caput of AI astatine Hex, introduced maine to what helium calls a “capability funnel” attack to AI roadmaps. This strategy reframes however we deliberation astir AI improvement progress. Instead of defining occurrence arsenic shipping a feature, the capableness funnel breaks down AI show into progressive levels of utility. At the apical of the funnel is the astir basal functionality: Can the strategy respond astatine all? At the bottommost is afloat solving the user’s occupation to beryllium done. Between these points are assorted stages of expanding usefulness.
For example, successful a query assistant, the capableness funnel mightiness look like:
- Can make syntactically valid queries (basic functionality)
- Can make queries that execute without errors
- Can make queries that instrumentality applicable results
- Can make queries that lucifer idiosyncratic intent
- Can make optimal queries that lick the user’s occupation (complete solution)
This attack acknowledges that AI advancement isn’t binary—it’s astir gradually improving capabilities crossed aggregate dimensions. It besides provides a model for measuring advancement adjacent erstwhile you haven’t reached the last goal.
The astir palmy teams I’ve worked with operation their roadmaps astir experiments alternatively than features. Instead of committing to circumstantial outcomes, they perpetrate to a cadence of experimentation, learning, and iteration.
Eugene Yan, an applied idiosyncratic astatine Amazon, shared however helium approaches ML task readying with leadership—a process that, portion primitively developed for accepted instrumentality learning, applies arsenic good to modern LLM development:
Here’s a communal timeline. First, I instrumentality 2 weeks to bash a information feasibility analysis, i.e., “Do I person the close data?”…Then I instrumentality an further period to bash a method feasibility analysis, i.e., “Can AI lick this?” After that, if it inactive works I’ll walk six weeks gathering a prototype we tin A/B test.
While LLMs mightiness not necessitate the aforesaid benignant of diagnostic engineering oregon exemplary grooming arsenic accepted ML, the underlying rule remains the same: time-box your exploration, found wide determination points, and absorption connected proving feasibility earlier committing to afloat implementation. This attack gives enactment assurance that resources won’t beryllium wasted connected open-ended exploration, portion giving the squad the state to larn and accommodate arsenic they go.
The Foundation: Evaluation Infrastructure
The cardinal to making an experiment-based roadmap enactment is having robust valuation infrastructure. Without it, you’re conscionable guessing whether your experiments are working. With it, you tin rapidly iterate, trial hypotheses, and physique connected successes.
I saw this firsthand during the aboriginal improvement of GitHub Copilot. What astir radical don’t recognize is that the squad invested heavy successful gathering blase offline valuation infrastructure. They created systems that could trial codification completions against a precise ample corpus of repositories connected GitHub, leveraging portion tests that already existed successful high-quality codebases arsenic an automated mode to verify completion correctness. This was a monolithic engineering undertaking—they had to physique systems that could clone repositories astatine scale, acceptable up their environments, tally their trial suites, and analyse the results, each portion handling the unthinkable diverseness of programming languages, frameworks, and investigating approaches.
This wasn’t wasted time—it was the instauration that accelerated everything. With coagulated valuation successful place, the squad ran thousands of experiments, rapidly identified what worked, and could accidental with assurance “This alteration improved prime by X%” alternatively of relying connected gut feelings. While the upfront concern successful valuation feels slow, it prevents endless debates astir whether changes assistance oregon wounded and dramatically speeds up innovation later.
Communicating This to Stakeholders
The challenge, of course, is that executives often privation certainty. They privation to cognize erstwhile features volition vessel and what they’ll do. How bash you span this gap?
The cardinal is to displacement the speech from outputs to outcomes. Instead of promising circumstantial features by circumstantial dates, perpetrate to a process that volition maximize the chances of achieving the desired concern outcomes.
Eugene shared however helium handles these conversations:
I effort to reassure enactment with timeboxes. At the extremity of 3 months, if it works out, past we determination it to production. At immoderate measurement of the way, if it doesn’t enactment out, we pivot.
This attack gives stakeholders wide determination points portion acknowledging the inherent uncertainty successful AI development. It besides helps negociate expectations astir timelines—instead of promising a diagnostic successful six months, you’re promising a wide knowing of whether that diagnostic is feasible successful 3 months.
Bryan’s capableness funnel attack provides different almighty connection tool. It allows teams to amusement factual advancement done the funnel stages, adjacent erstwhile the last solution isn’t ready. It besides helps executives recognize wherever problems are occurring and marque informed decisions astir wherever to put resources.
Build a Culture of Experimentation Through Failure Sharing
Perhaps the astir counterintuitive facet of this attack is the accent connected learning from failures. In accepted bundle development, failures are often hidden oregon downplayed. In AI development, they’re the superior root of learning.
Eugene operationalizes this astatine his enactment done what helium calls a “fifteen-five”—a play update that takes 15 minutes to constitute and 5 minutes to read:
In my fifteen-fives, I papers my failures and my successes. Within our team, we besides person play “no-prep sharing sessions” wherever we sermon what we’ve been moving connected and what we’ve learned. When I bash this, I spell retired of my mode to stock failures.
This signifier normalizes nonaccomplishment arsenic portion of the learning process. It shows that adjacent experienced practitioners brushwood dead-ends, and it accelerates squad learning by sharing those experiences openly. And by celebrating the process of experimentation alternatively than conscionable the outcomes, teams make an situation wherever radical consciousness harmless taking risks and learning from failures.
A Better Way Forward
So what does an experiment-based roadmap look similar successful practice? Here’s a simplified illustration from a contented moderation task Eugene worked on:
I was asked to bash contented moderation. I said, “It’s uncertain whether we’ll conscionable that goal. It’s uncertain adjacent if that extremity is feasible with our data, oregon what instrumentality learning techniques would work. But here’s my experimentation roadmap. Here are the techniques I’m gonna try, and I’m gonna update you astatine a two-week cadence.”
The roadmap didn’t committedness circumstantial features oregon capabilities. Instead, it committed to a systematic exploration of imaginable approaches, with regular check-ins to measure advancement and pivot if necessary.
The results were telling:
For the archetypal 2 to 3 months, thing worked. . . .And past [a breakthrough] came out. . . .Within a month, that occupation was solved. So you tin spot that successful the archetypal 4th oregon adjacent 4 months, it was going nowhere. . . .But past you tin besides spot that each of a sudden, immoderate caller technology…, immoderate caller paradigm, immoderate caller reframing comes on that conscionable [solves] 80% of [the problem].
This pattern—long periods of evident nonaccomplishment followed by breakthroughs—is communal successful AI development. Traditional feature-based roadmaps would person killed the task aft months of “failure,” missing the eventual breakthrough.
By focusing connected experiments alternatively than features, teams make abstraction for these breakthroughs to emerge. They besides physique the infrastructure and processes that marque breakthroughs much likely: information pipelines, valuation frameworks, and accelerated iteration cycles.
The astir palmy teams I’ve worked with commencement by gathering valuation infrastructure earlier committing to circumstantial features. They make tools that marque iteration faster and absorption connected processes that enactment accelerated experimentation. This attack mightiness look slower astatine first, but it dramatically accelerates improvement successful the agelong tally by enabling teams to larn and accommodate quickly.
The cardinal metric for AI roadmaps isn’t features shipped—it’s experiments run. The teams that triumph are those that tin tally much experiments, larn faster, and iterate much rapidly than their competitors. And the instauration for this accelerated experimentation is ever the same: robust, trusted valuation infrastructure that gives everyone assurance successful the results.
By reframing your roadmap astir experiments alternatively than features, you make the conditions for akin breakthroughs successful your ain organization.
Conclusion
Throughout this post, I’ve shared patterns I’ve observed crossed dozens of AI implementations. The astir palmy teams aren’t the ones with the astir blase tools oregon the astir precocious models—they’re the ones that maestro the fundamentals of measurement, iteration, and learning.
The halfway principles are amazingly simple:
- Look astatine your data. Nothing replaces the penetration gained from examining existent examples. Error investigation consistently reveals the highest-ROI improvements.
- Build elemental tools that region friction. Custom information viewers that marque it casual to analyse AI outputs output much insights than analyzable dashboards with generic metrics.
- Empower domain experts. The radical who recognize your domain champion are often the ones who tin astir efficaciously amended your AI, careless of their method background.
- Use synthetic information strategically. You don’t request existent users to commencement investigating and improving your AI. Thoughtfully generated synthetic information tin bootstrap your valuation process.
- Maintain spot successful your evaluations. Binary judgments with elaborate critiques make clarity portion preserving nuance. Regular alignment checks guarantee automated evaluations stay trustworthy.
- Structure roadmaps astir experiments, not features. Commit to a cadence of experimentation and learning alternatively than circumstantial outcomes by circumstantial dates.
These principles use careless of your domain, squad size, oregon method stack. They’ve worked for companies ranging from early-stage startups to tech giants, crossed usage cases from lawsuit enactment to codification generation.
Resources for Going Deeper
If you’d similar to research these topics further, present are immoderate resources that mightiness help:
- My blog for much contented connected AI valuation and improvement. My different posts dive into much method item connected topics specified arsenic constructing effectual LLM judges, implementing valuation systems, and different aspects of AI development.1 Also cheque retired the blogs of Shreya Shankar and Eugene Yan, who are besides large sources of accusation connected these topics.
- A people I’m teaching, Rapidly Improve AI Products with Evals, with Shreya Shankar. It provides hands-on acquisition with techniques specified arsenic mistake analysis, synthetic information generation, and gathering trustworthy valuation systems, and includes applicable exercises and personalized acquisition done bureau hours.
- If you’re looking for hands-on guidance circumstantial to your organization’s needs, you tin larn much astir moving with maine astatine Parlance Labs.
Footnotes
- I constitute much broadly astir instrumentality learning, AI, and bundle development. Some posts that grow connected these topics see “Your AI Product Needs Evals,” “Creating a LLM-as-a-Judge That Drives Business Results,” and “What We’ve Learned from a Year of Building with LLMs.” You tin spot each my posts astatine hamel.dev.








 English (US) ·
English (US) ·